The open-source data layer for AI coding sessions
OpenStory turns every session into a shared, searchable, real-time data stream — so your team can see what developers and their agents are actually doing, the moment it happens.
Start local. Share when you choose to.
The same open stream powers a private retrospective for one engineer and a live, consent-scoped feed for a whole team.
OpenStory Local
An engineering retrospective for one
Point it at your own sessions and they become a mirror of how you actually work — your collaboration style, what you investigate versus ship, how your thinking drifts over time. None of it lives in git history.
- Local-first — SQLite + JSONL on your disk
- Every turn narrated as a plain-English sentence
- Search and replay your entire history
- Private by default — nothing leaves the laptop
OpenStory Stream
BetaFleet observability for a team
Subscribe to teammates' sessions, consent-scoped, and watch work happen live across machines, networks, and time zones. Auto-generated reports on a cadence replace standups and 1:1 status pings.
- Subscribe to teammates, consent-scoped
- Live across machines & networks
- Auto markdown reports replace standups
- Leaders see the real agentic SDLC
You and your fleet of devices
Your laptop, an OpenClaw box, a Hermes agent — every device you run streams into one private place. Sync your own fleet first; uniting fleets across a team comes next.
Four pieces. Nothing magic.
A read-only watcher turns raw agent transcripts into a durable, replayable event stream — then four independent consumers each do one job.
Agent works
Your coding agent writes JSONL transcripts as it runs — Claude Code, pi-mono, Hermes.
Watch & translate
A read-only watcher detects the format and translates each line into CloudEvents 1.0.
Stream over NATS
Events flow through NATS JetStream — durable, replayable, hierarchically addressed.
Four consumers
Persist, patterns, projections, and broadcast each own one job and never block each other.
events.{project}.{session}.agent.{agent_id}NATS subjects encode the agent hierarchy — so subagent delegation is structural, not guessed.
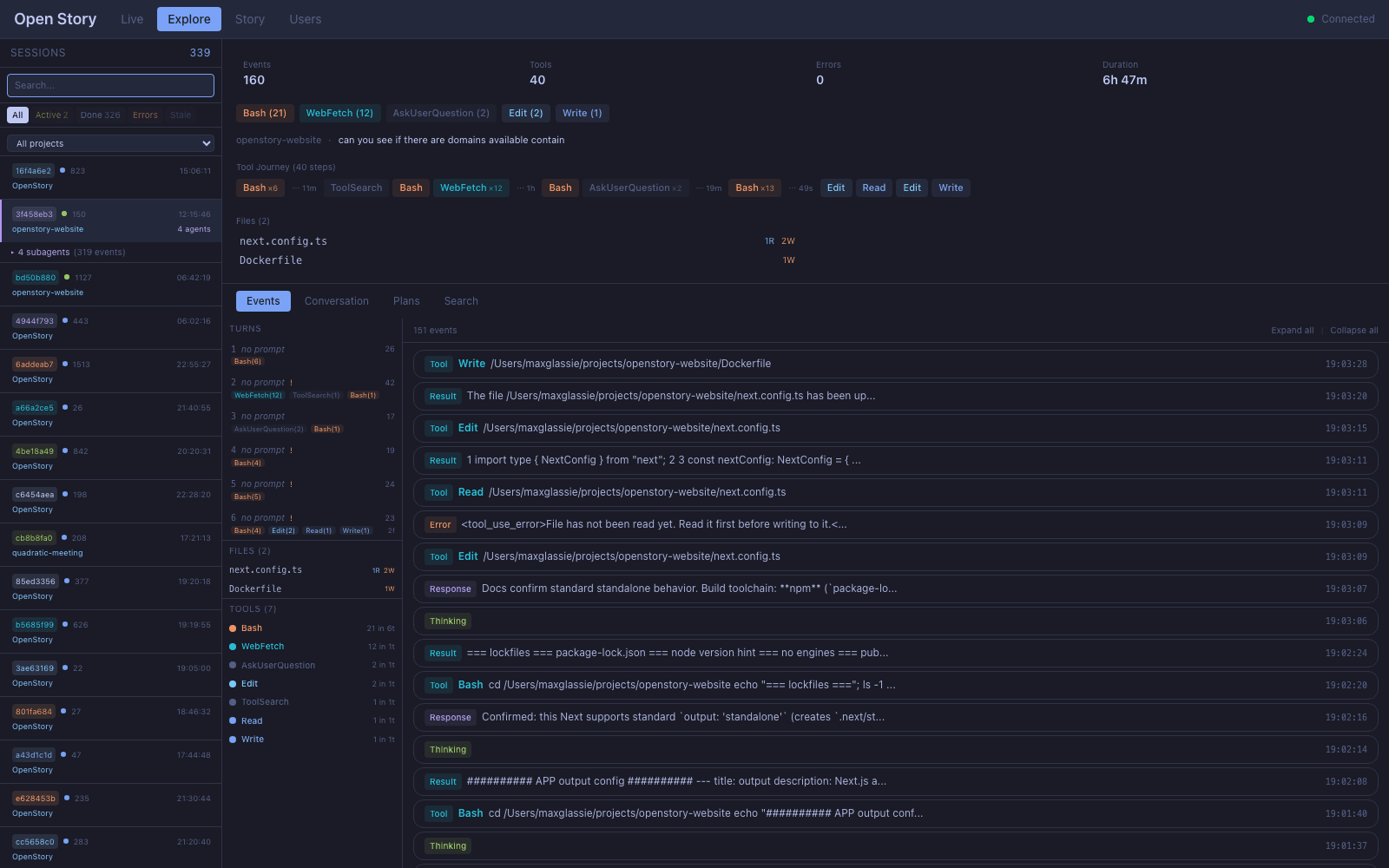
From firehose to one sentence
Every completed turn is folded into a single readable line — subject, verb, what it read, what it ran, and why. The whole turn, legible at a glance.
ClaudeeditedTurnCard.tsxafter reading 3 files,while running 4 checks,because“can we surface the UUIDs?”→ answered
Every session, three ways to see it
The same CloudEvents, projected into the view you need — from the live firehose to a single readable sentence.
Live
Watch every move as it happens
A real-time event stream of every tool call, file read, command, and model response — the moment your agent does it. The session sidebar tracks active sessions with token usage, depth sparklines, and the full subagent hierarchy.
Story
Each turn becomes a sentence
Every completed turn is parsed into one English sentence — subject, verb, what it read, what it ran, and why. Click a card and the full eval-apply trace unfolds: the input, the tool applications, and the model's final answer.
Explore
Search across every session
Full-text search and filtering across your entire history. Compare sessions, jump to any event, and reconstruct exactly what happened — backed by FTS5 and durable, replayable storage.
Backed by working code and real data
Not mockups. Every claim below is measured from sessions OpenStory recorded about its own work.
Engineering retrospective for an individual
Turn an engineer's sessions into a mirror of how they actually work — collaboration style, vocabulary drift, what they investigate versus ship. None of it visible in git history.
86 days of one engineer's sessions produced a working portrait: they treat the model as a collaborator (2.7× more dialogic than imperative), they read 6× more than they write.
Fleet observability for a team lead
Subscribe to teammates' sessions, consent-scoped. Get auto-generated markdown reports on a 30-minute cadence. Replaces standups and 1:1 status pings.
A subscriber on one laptop watched a different agent on a different machine, across a different network, in real time for 90+ minutes.
Provenance & cost attribution per prompt
Every file that gets created traces back to the exact prompt that asked for it. Every prompt has a measured token cost. Deterministic, auditable, billable.
A single prompt produced 16 new files at 40,794 output tokens — the lineage is provable end-to-end. Two reflective queries cost $0.12 exactly, verified to the penny against the model's own cost record.
What 156 sessions say about how one engineer works
No mockups. We pointed OpenStory at 1,180 of its own maker's prompts — proof case 01, for real. Here is the working portrait it produced.
The data describes a collaborative pair-programmer, not a commander: more questions than orders, “we” a quarter of the time, and a median prompt of just eleven words — quick, trusting nudges instead of long specs.
How you ask
What you talk about
Top things you ask for
A mirror, not a leash
We're building open-source on purpose. People and companies want sovereignty over the story of their work.
Observe, never interfere
Zero write operations on watched paths. OpenStory reads transcripts; it never edits, blocks, or talks back. A mirror, not a leash.
Your data, open formats
Every event is appended to plain JSONL on disk in CloudEvents 1.0 — grep-able from outside the database, useful without this tool, impossible to lock in.
Local-first by default
Nothing leaves your machine. SQLite out of the box, MongoDB when you need scale, the same data either way.
Recursive observability
OpenStory produces legible sentences for its own sessions. It was built by pointing it at itself — and the proof is in the repo.
Up and running in one command
Local-first by default. Pick your path — your data never leaves your machine.
$brew tap OpenStoryArc/openstory$brew install openstory $open-story init --data-dir "$(brew --prefix)/var/openstory"$brew services start openstory # auto-start at login➜ Opens at http://localhost:3002
Own the story of your work
Open source, platform-agnostic, and local-first. See what you and your agents are actually doing — and keep the data.